
香山GEM5对齐记录 lbm_7139_0.400131
lbm_7139_0.400131
整体时钟分析
| 执行IPC | 指令数量 | 执行时钟 | |
|---|---|---|---|
| GEM5 | 0.9634 | 20000001 | 20758359 |
| RTL | 0.8313 | 19999995 | 24,056,825 |
| 多3, 298, 466 | |||
| GEM5时钟 | RTL时钟 | 时钟差 | |
| 修复Gem5 fdiv.d 后 | 21,851,033 | 24,056,825 | 2,205,792 |
| 修复RTL ddr时钟后 | 21,851,033 | 23,792,907 | 1,941,874 |
基本块分析
| 地址 | 指令 | 执行次数 | 增加时钟 | 多余总时钟 | 占比 | 原因 | 现状 |
|---|---|---|---|---|---|---|---|
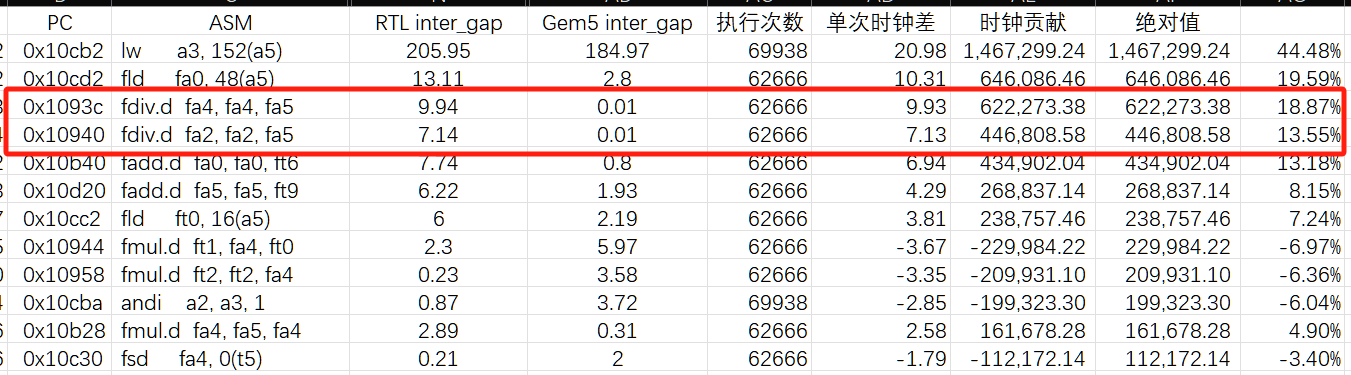
| 0x10cb2 | lw a3, 152(a5) | 69938 | 20.98 | 1,467,299 | 44. 48% | RTL DRAMSim3时钟错误 | ✅已消除 |
| 0x10cd2 | fld fa0, 48(a5) | 62666 | 10.31 | 646,086 | 19.59% | RTL DRAMSim3时钟错误 | ✅已消除 |
| 0x1093c | fdiv.d fa4, fa4, fa5 | 62666 | 9.93 | 622,273.38 | 18.87% | div加速没对齐 | ✅已消除 |
| 0x10940 | fdiv.d fa2, fa2, fa5 | 62666 | 7.13 | 446,808.58 | 13.55% | div加速没对齐 | ✅已消除 |
指令分析
0x10cb2 lw a3, 152(a5)
| 执行IPC | 指令数量 | 执行时钟 | |
|---|---|---|---|
| GEM5 | 0.9152 | 20000000 | 21851033 |
| RTL | 0.8406 | 20000000 | 23,792,907 |
| 多3, 298, 466 | |||
| 修复 fdiv.d 后 |
inter gap 锁定指令
RTL 平均比 Gem5 提交多21拍
RTL inter-gap
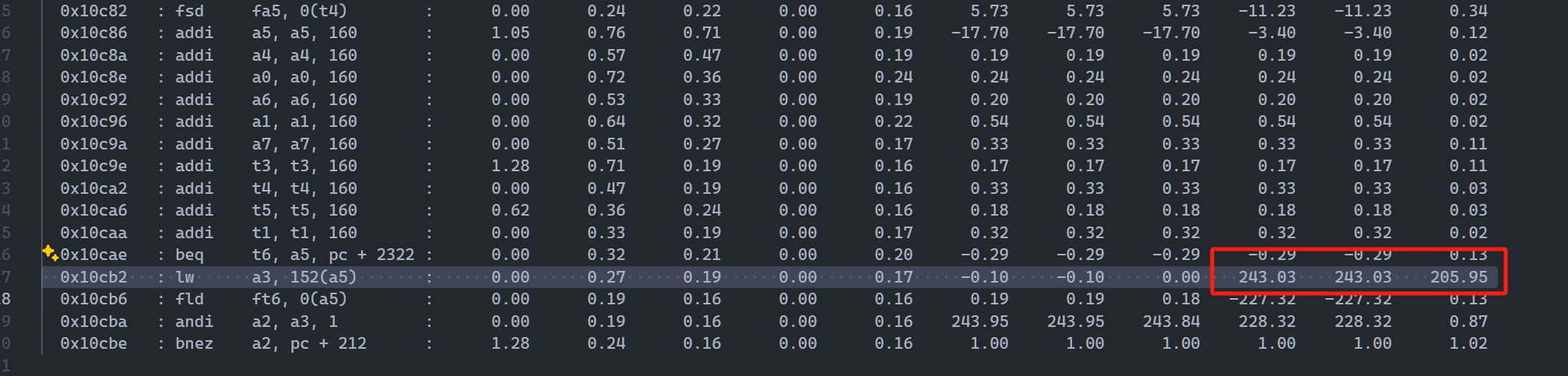
Gem5 inter-gap
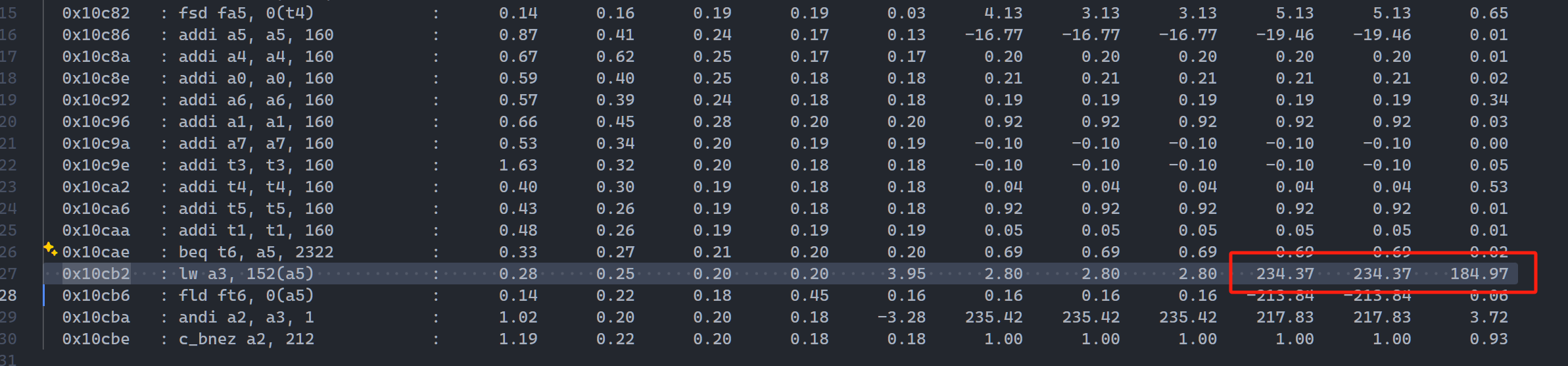
inner gap锁定阶段
在 exec -> bypass 多了 12拍,访存存在问题
RTL inner-gap

Gem5 inner-gap

1000 拍以内的时钟访存时延累加基本相同,1000拍以上的数量 RTL约为 Gem5 一倍。可能是
- DDR刚好卡在DDR刷新附近引起这个问题,延迟会突然出现一个暴增。
- DDR队列不足,这条访存被堵住,延迟时钟就累加上来了。
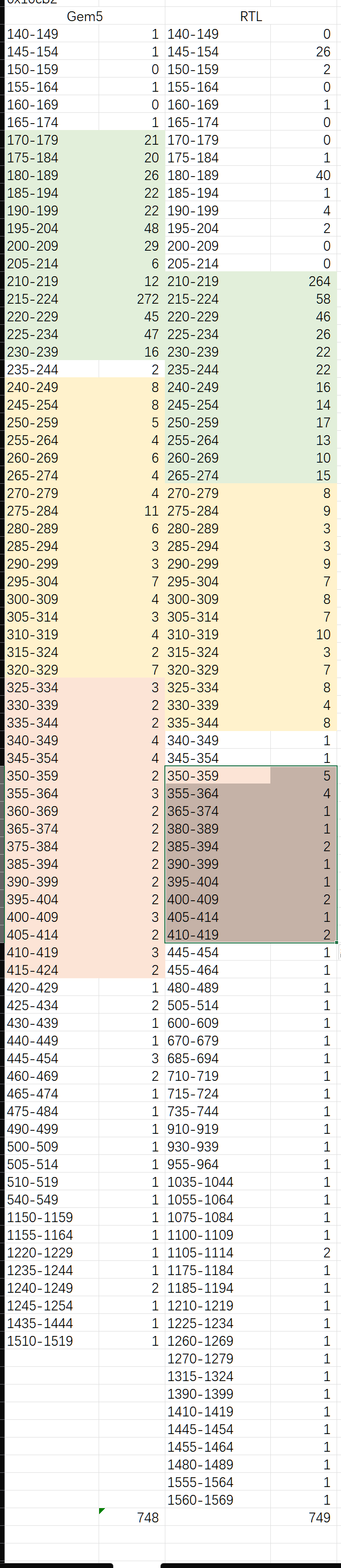
inner gap pc only 异常时钟分析
仅抓取 0x10cb2 这条指令的 inner gap分析,发现1000拍出现并没有一个累加上来的过程,而是突然出现一下,两边都一样。因此应该不是DDR访存队列堵住了。
分析 1000 拍以上延迟出现的频率,发现发生的循环数之间非常有规律:
Gem5:47 123 199 大约76循环一次。
RTL:32 64 97 165 199 232,大约32-34循环一次。
因此基本断定就是 DDR刷新问题导致的,1000拍以上数量摊到每次循环中,确实是10拍多的差距。
刷新时钟分析
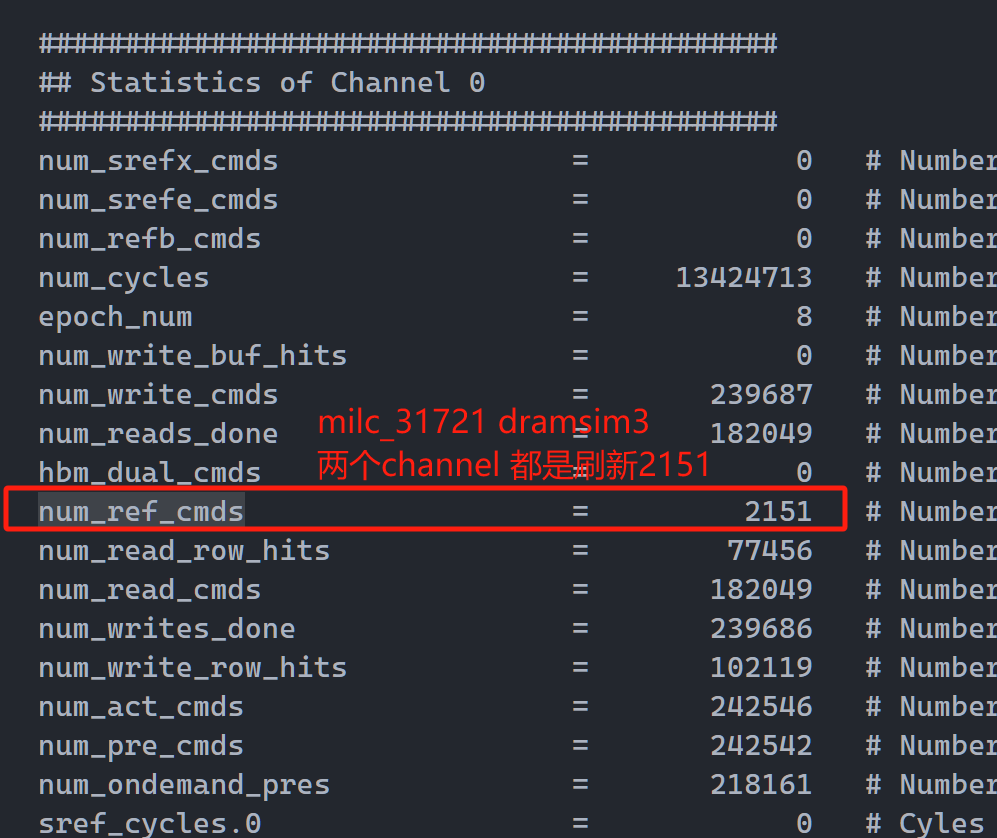
下面的实验数据来自于具有相似问题的另外一个测试点 milc_31721_0.115315。
Gem5
RTL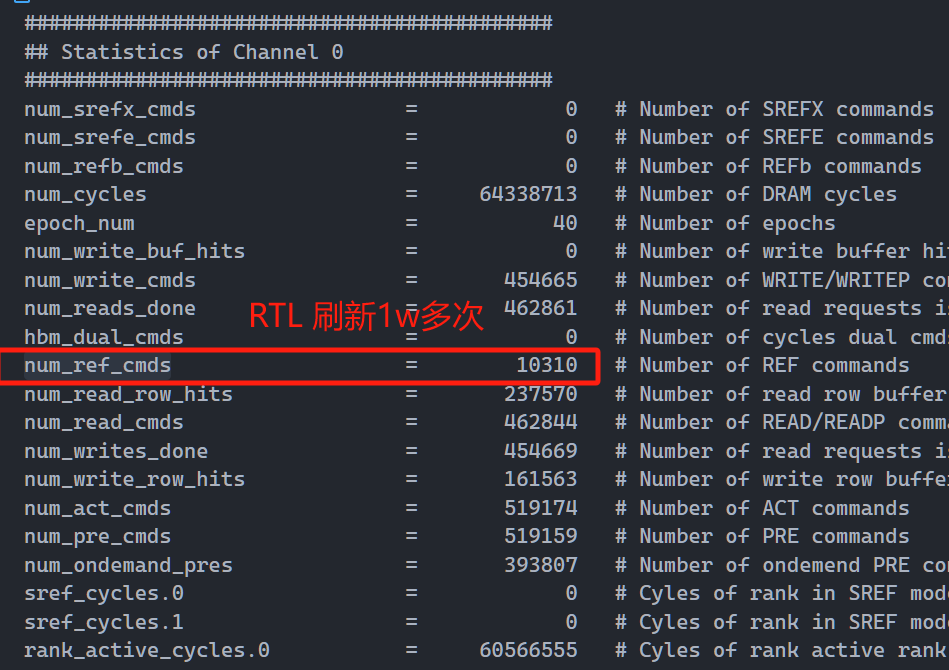
观察到,RTL刷新次数10310(含预热),按比例扣除预热后为5163。Gem5上的DRAMSim3刷新次数为2151,这个次数与我们观察到的刷新次数RTL 比 Gem5 多接近 1 倍相接近——确定为刷新频率问题。
下面计算刷新频率,刷新间隔 = num_cycles / num_ref_cmds,在两个处理器上都是 6240 clock(这个clock是dramsim3的clock),故刷新的频率对于 dramsim3 模拟器自身来说应该是对齐的。
但是我发现一个问题:
RTL 上统计的
DRAMSim3 num_cycle(含预热)是 64, 338, 713,CPU clock_cycle(含预热)也是64, 338, 713,即RTL模拟器上CPU时钟数与DRAMSim3钟数相同,这显然违反了我对 CPU 运行速度和内存运行速度的直觉(理论上CPU频率远大于DDR频率)。在Gem5上发现
DRAMSim3 num_cycle(不含预热)是 13, 424, 713,CPU num_cycle(不含预热)是 25, 398, 106,CPU Clock : DRAMSim3 Clock = 1.89。
下面根据配置计算合理性:
- CPU 频率为3GHz
- DRAMSim3配置文件
xiangshan_DDR4_8Gb_x8_3200_2ch定义为 0.63 ns / clock 即 1.587 GHz - 运行相同时间,CPU 时钟数 : DRAMSim3 时钟数量 = 3 GHz : 1.587 GHz = 1.89 为合理。
综上,Gem5模型中 CPU 时钟与 DRAMSim3 时钟比例是正确的,而 RTL 错把 CPU时钟作为 DDR 时钟。
实现确认
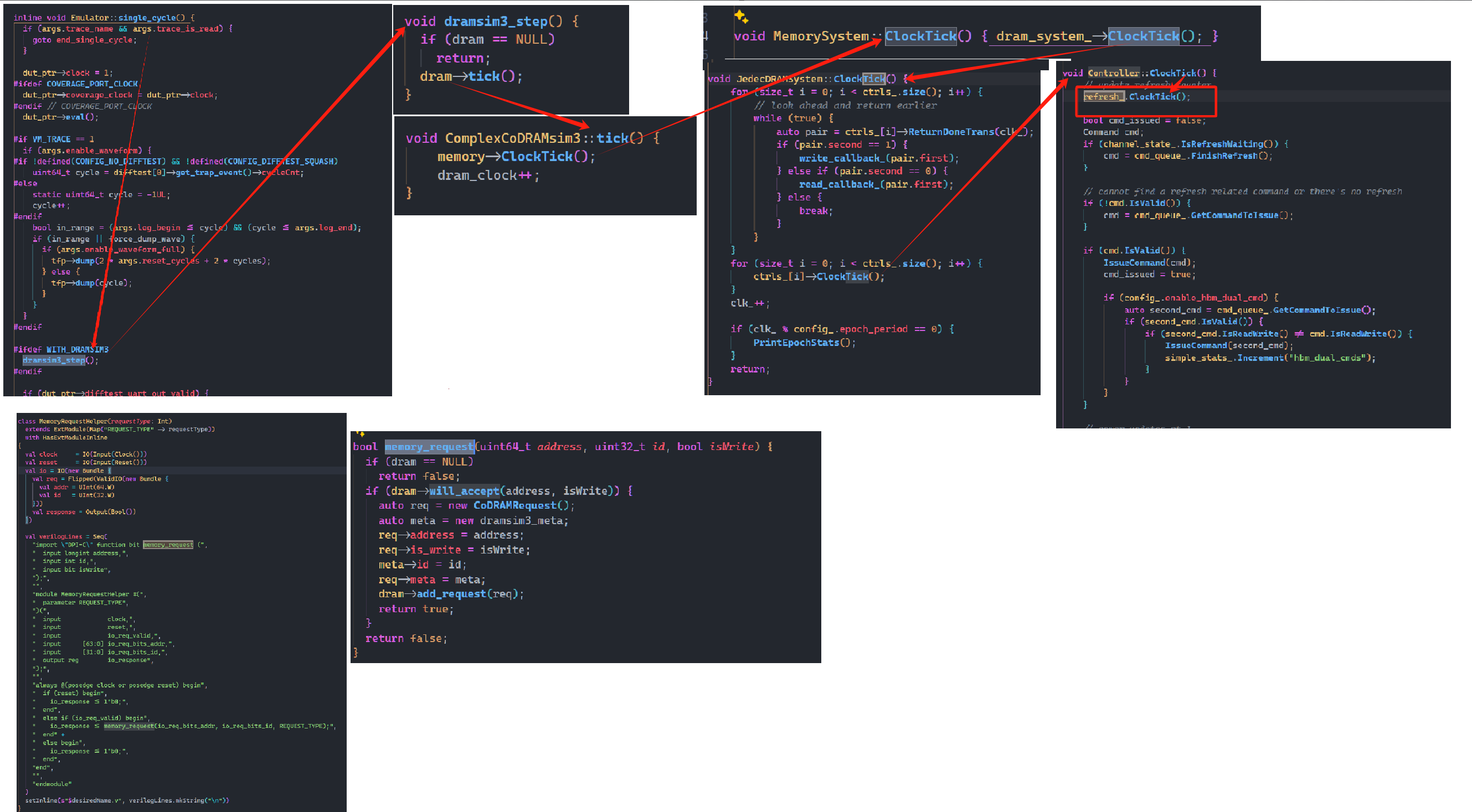
从函数调用来看,确实是在RTL中 DRAMSim3与CPU使用同一个时钟。
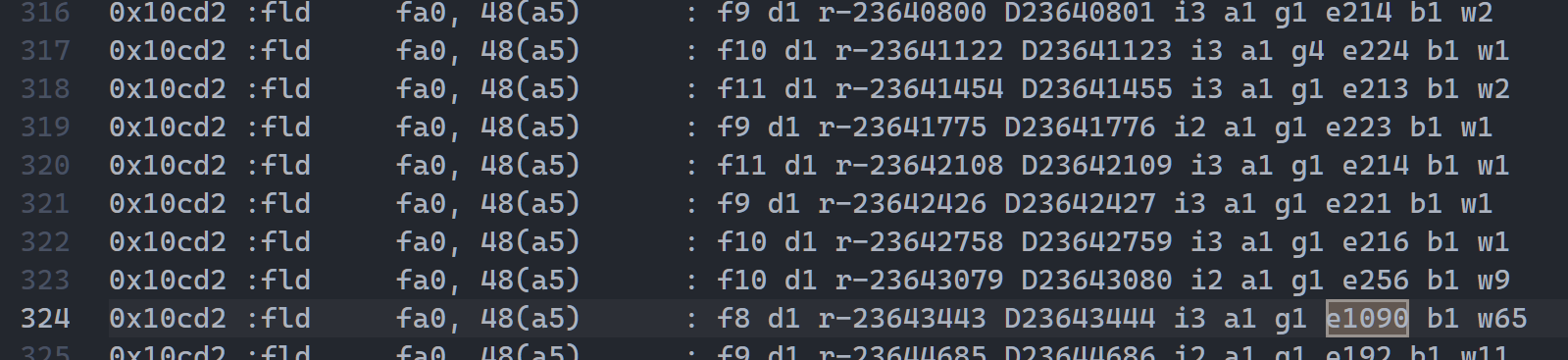
0x10cd2 fld fa0, 48(a5)
原因同 0x10cb2
0x1093c fdiv.d fa4, fa4, fa5
问题描述
exec -> bypass 即浮点运算指令时钟在 Gem5 上有 1 拍,而在 RTL上有 11 拍,有10拍左右的时钟差
问题发现
通过基本块分析获得各基本块执行次数,配合 perfcct 获得指令各阶段的时钟位置。每条指令的 commit 减去上一条指令的 commit,得到本条指令相对前一条指令的提交时间指令的平均 inter_gap。
Gem5 inter_gap

RTL inter_gap

每条指令的时钟贡献 = $ inter_gap * 执行次数$,根据贡献时钟绝对值排序获得影响最大的几条指令,其中 0x1093c fdiv.d fa4, fa4, fa5 排名第三和第四。加起来有32%的时钟贡献。
定位 miss match
抓取 0x1093c 前后提交指令,寻找通过计算 inner_gap(指令内部后一阶段开始时间减去前一阶段开始)确定典型场景。
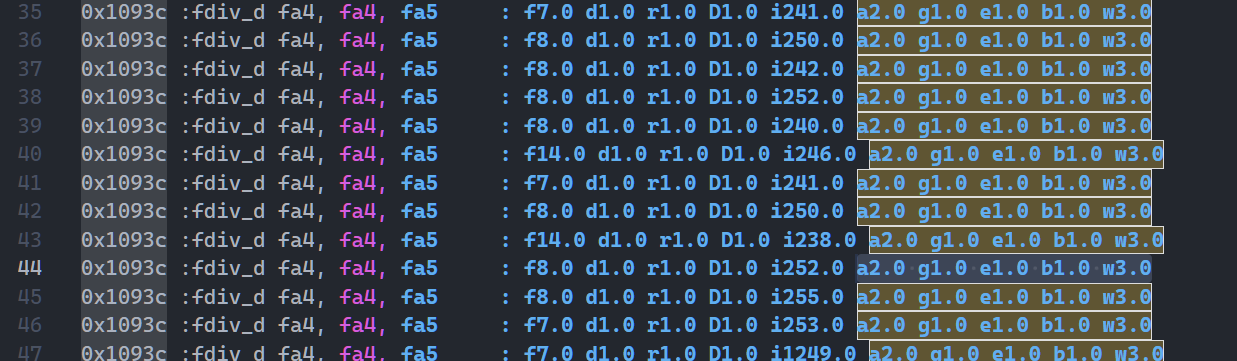
发现 0x1093c这条指令在 exec -> bypass 也就是浮点执行阶段的时钟周期不匹配(Gem5 1拍,RTL 11拍)
图1,RTL perfcct 原始数据
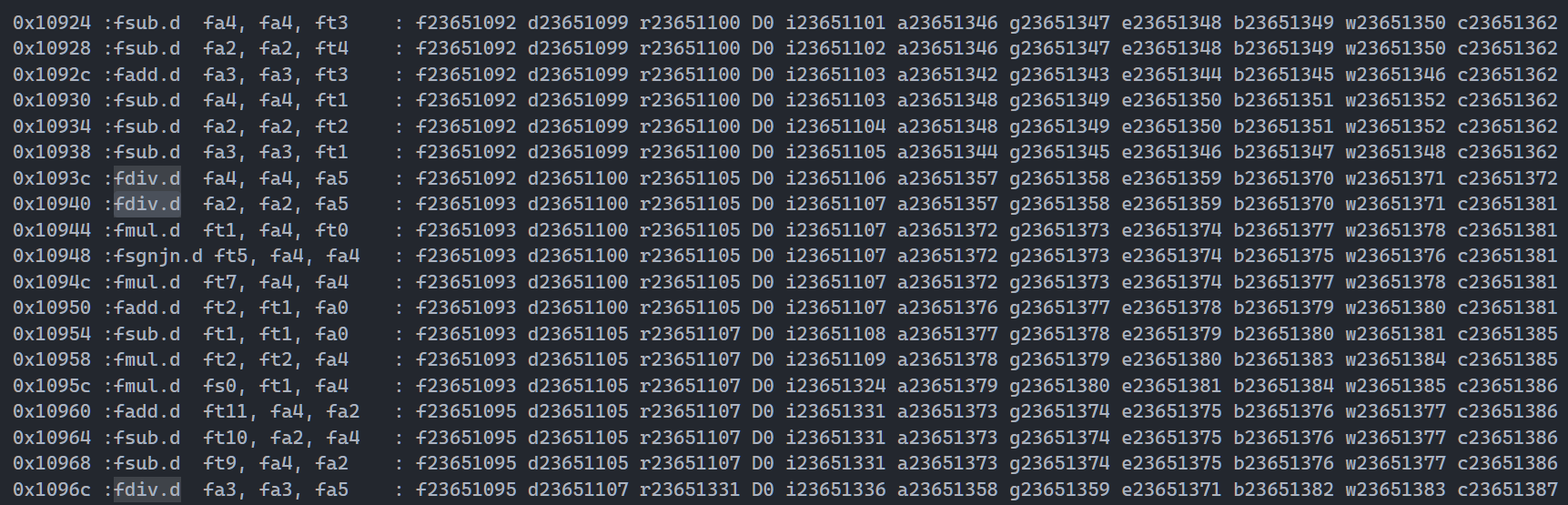
图2,RTL inner_gap
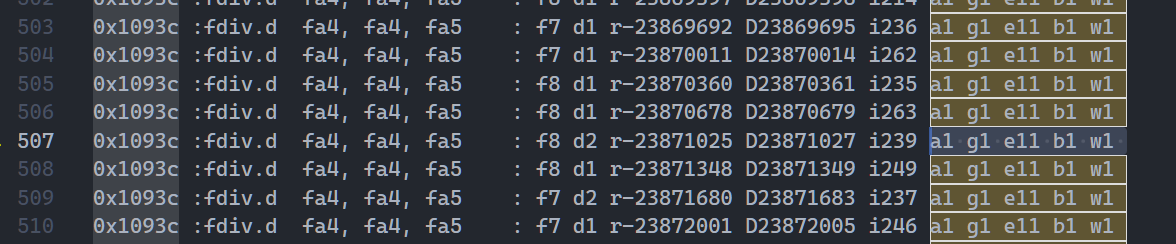
图3,Gem5 perfcct 原始数据
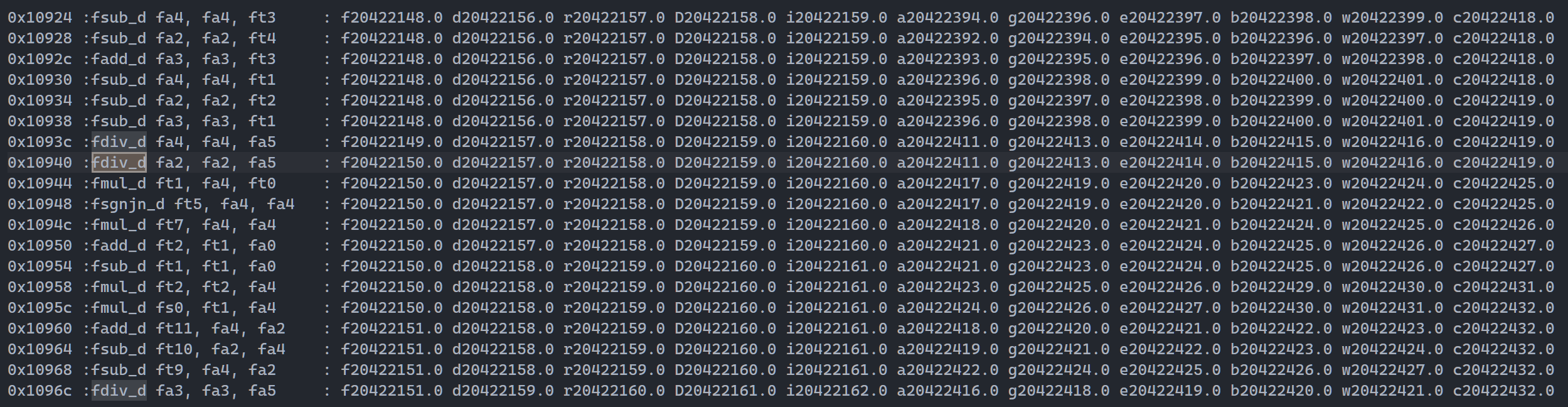
图4,gem5-inner-gap
结论
浮点运算模块行为不匹配导致的错误。具体原因和RTL组交流得知,RTL未实现“除1”优化,建议在 Gem5 模型删除这个 feature。
0x10940 fdiv.d fa2, fa2, fa5
问题同 0x10c93
总结
主要潜在问题有两个:
- DIV 指令加速未对齐,RTL未实现“除1”优化,建议在 Gem5 模型删除这个 feature。
- DDR行为存在问题,导致RTL上的 DDR 出现上前拍 load 延迟的情况约为 Gem5 的两倍。